

多因子策略
(注:以下部分内容引用自《因子投资:方法与实践》一书)
1. 原理
多因子策略是最广泛应用的策略之一。CAPM模型的提出为股票的收益提供了解释,但随着各种市场异象的出现,使得人们发现股票存在超额收益,这种收益不能为市场因子所解释,因此,出现了多因子模型。
多因子模型最早是由Fama-French提出,包括三因子和五因子模型。Fama认为,股票的超额收益可以由市场因子、市值因子和账面价值比因子共同解释。随着市场的发展,出现许多三因子模型难以解释的现象。因此,Fama又提出了五因子模型,加入了盈利水平、投资水平因子。
此后,陆续出现了六因子模型、八因子模型等,目前多少个因子是合适的尚无定论。
市场上常用的多因子模型包括如下几个。
| 模型 | 出处 | 所含因子 |
|---|---|---|
| Fama-French三因子 | Fama and Farench(1993) | 市场、规模、价值 |
| Carhart四因子 | Carhart(1997) | 市场、规模、价值、动量 |
| Novy-Marx四因子 | Novy-Marx(2013) | 市场、规模、价值、盈利 |
| Fama-French五因子 | Fama and Farench(2015) | 市场、规模、价值、盈利、投资 |
| Hou-Xue-Zhang四因子 | Hou et al | 市场、规模、盈利、投资 |
| Stambaugh-Yuan四因子 | Stambaugh and Yuan(2017) | 市场、规模、管理、表现 |
| Daniel-Hirshleifer-Sun三因子 | Daniel et al(2020) | 市场、长周期行为、短周期行为 |
本策略以Fama提出的三因子模型作为基础。
Fama-French三因子模型
在多因子模型出现以前,CAPM模型被奉为典型,几乎所有定价均是按照CAPM模型计算的。后来学者们发现了各种异象,这些异象无法用CAPM模型解释。较为典型的有Basu发现的盈利市值比效应和Banz发现的小市值效应。遗憾的是,虽然单一异象被发现后都对CAPM提出了挑战,但并没有形成合力,直到Fama三因子模型出现。
Fama等人在CAPM的基础上,Fama加入了HML和SMB两个因子,提出了三因子模型,也是多因子模型的基础。
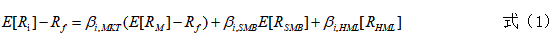
其中E[R_i]代表股票i的预期收益率,R_f代表无风险收益率,E[R_m]为市场组合预期收益率,E[R_SMB]和E[R_HML]分别为规模因子收益率和价值因子预期收益率。
为构建价值因子和规模因子,Fama选择BM和市值两个指标进行双重排序,将股票分为大市值组B和小市值组S;按照账面市值比将股票分为BM高于70%分位数的H组,BM低于30%分位数的L组,BM处于二者之间的记为M组。如表所示。
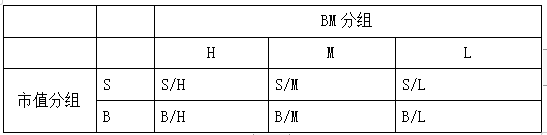
得到上述分组以后,就可以构建规模和价值两个因子。
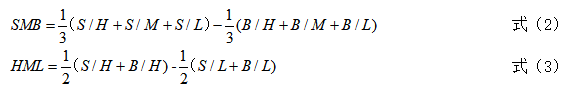
上述式子解释一下可以发现,规模因子是三个小市值组合的等权平均减去三个大市值组合的等权平均;价值因子是两个高BM组合的等权平均减去两个低BM组合的等权平均。
策略设计思路(假设三因子模型是完全有效的)
在用三因子模型估算股票预期收益率时,经常会发现并非每只股票都能严格吻合式1,大部分股票都会存在一个alpha截距项。当存在alpha截距项时,说明股票当前价格偏离均衡价格。基于此,可以设计套利策略。
alpha < 0时,说明股票收益率低于均衡水平,股票价格被低估,应该买入。
alpha > 0时,说明股票收益率高于均衡水平,股票价格被高估,应该卖出。
因此,可以获取alpha最小并且小于0的10只的股票买入开仓。
2. 策略步骤
第一步:获取股票市值以及账面市值比数据。
第二步:将股票按照各个因子进行排序分组,分组方法如上表所示。
第三步:依据式2式3,计算SMB、HML因子。
第四步:因子回归,计算alpha值。获取alpha最小并且小于0的10只的股票买入开仓。
回测期:2017-07-01 8:00:00 至 2017-10-01 16:00:00
回测初始资金:1000万
回测标的:沪深300成分股
3. 策略代码
# coding=utf-8from __future__ import print_function, absolute_import, unicode_literalsimport numpy as npfrom gm.api import *from pandas import DataFrame'''本策略每隔1个月定时触发,根据Fama-French三因子模型对每只股票进行回归,得到其alpha值。假设Fama-French三因子模型可以完全解释市场,则alpha为负表明市场低估该股,因此应该买入。策略思路:计算市场收益率、个股的账面市值比和市值,并对后两个进行了分类,根据分类得到的组合分别计算其市值加权收益率、SMB和HML.对各个股票进行回归(假设无风险收益率等于0)得到alpha值.选取alpha值小于0并为最小的10只股票进入标的池平掉不在标的池的股票并等权买入在标的池的股票回测数据:SHSE.000300的成份股回测时间:2017-07-01 08:00:00到2017-10-01 16:00:00'''def init(context):# 每月第一个交易日的09:40 定时执行algo任务(仿真和实盘时不支持该频率)schedule(schedule_func=algo, date_rule='1m', time_rule='09:40:00')# 数据滑窗context.date = 20# 设置开仓的最大资金量context.ratio = 0.8# 账面市值比的大/中/小分类context.BM_BIG = 3.0context.BM_MID = 2.0context.BM_SMA = 1.0# 市值大/小分类context.MV_BIG = 2.0context.MV_SMA = 1.0# 计算市值加权的收益率的函数,MV为市值的分类对应的组别,BM为账目市值比的分类对应的组别def market_value_weighted(stocks, MV, BM):select = stocks[(stocks['NEGOTIABLEMV'] == MV) & (stocks.['BM'] == BM)] # 选出市值为MV,账目市值比为BM的所有股票数据market_value = select['mv'].values # 对应组的全部市值数据mv_total = np.sum(market_value) # 市值求和mv_weighted = [mv / mv_total for mv in market_value] # 市值加权的权重stock_return = select['return'].values# 返回市值加权的收益率的和return_total = []for i in range(len(mv_weighted)):return_total.append(mv_weighted[i] * stock_return[i])return_total = np.sum(return_total)return return_totaldef algo(context):# 获取上一个交易日的日期last_day = get_previous_trading_date(exchange='SHSE', date=context.now)# 获取沪深300成份股context.stock300 = get_history_constituents(index='SHSE.000300', start_date=last_day,end_date=last_day)[0]['constituents'].keys()# 获取当天有交易的股票not_suspended = get_history_instruments(symbols=context.stock300, start_date=last_day, end_date=last_day)not_suspended = [item['symbol'] for item in not_suspended if not item['is_suspended']]fin = get_fundamentals(table='trading_derivative_indicator', symbols=not_suspended,start_date=last_day, end_date=last_day,fields='PB,NEGOTIABLEMV', df=True) # 获取P/B和市值数据# 计算账面市值比,为P/B的倒数fin['PB'] = (fin['PB'] ** -1)# 计算市值的50%的分位点,用于后面的分类size_gate = fin['NEGOTIABLEMV'].quantile(0.50)# 计算账面市值比的30%和70%分位点,用于后面的分类bm_gate = [fin['PB'].quantile(0.30), fin['PB'].quantile(0.70)]fin.index = fin.symbol# 设置存放股票收益率的listx_return = []# 对未停牌的股票进行处理for symbol in not_suspended:# 计算收益率,存放到x_return里面close = history_n(symbol=symbol, frequency='1d', count=context.date + 1, end_time=last_day, fields='close',skip_suspended=True, fill_missing='Last', adjust=ADJUST_PREV, df=True)['close'].valuesstock_return = close[-1] / close[0] - 1pb = fin['PB'][symbol]market_value = fin['NEGOTIABLEMV'][symbol]# 获取[股票代码, 股票收益率, 账面市值比的分类, 市值的分类, 流通市值]# 其中账面市值比的分类为:大(3)、中(2)、小(1)# 流通市值的分类:大(2)、小(1)if pb < bm_gate[0]:if market_value < size_gate:label = [symbol, stock_return, context.BM_SMA, context.MV_SMA, market_value]else:label = [symbol, stock_return, context.BM_SMA, context.MV_BIG, market_value]elif pb < bm_gate[1]:if market_value < size_gate:label = [symbol, stock_return, context.BM_MID, context.MV_SMA, market_value]else:label = [symbol, stock_return, context.BM_MID, context.MV_BIG, market_value]elif market_value < size_gate:label = [symbol, stock_return, context.BM_BIG, context.MV_SMA, market_value]else:label = [symbol, stock_return, context.BM_BIG, context.MV_BIG, market_value]if len(x_return) == 0:x_return = labelelse:x_return = np.vstack([x_return, label])# 将股票代码、 股票收益率、 账面市值比的分类、 市值的分类、 流通市值存为数据表stocks = DataFrame(data=x_return, columns=['symbol', 'return', 'BM', 'NEGOTIABLEMV', 'mv'])stocks.index = stocks.symbolcolumns = ['return', 'BM', 'NEGOTIABLEMV', 'mv']for column in columns:stocks[column] = stocks[column].astype(np.float64)# 计算SMB.HML和市场收益率(市值加权法)smb_s = (market_value_weighted(stocks, context.MV_SMA, context.BM_SMA) +market_value_weighted(stocks, context.MV_SMA, context.BM_MID) +market_value_weighted(stocks, context.MV_SMA, context.BM_BIG)) / 3# 获取大市值组合的市值加权组合收益率smb_b = (market_value_weighted(stocks, context.MV_BIG, context.BM_SMA) +market_value_weighted(stocks, context.MV_BIG, context.BM_MID) +market_value_weighted(stocks, context.MV_BIG, context.BM_BIG)) / 3smb = smb_s - smb_b# 获取大账面市值比组合的市值加权组合收益率hml_b = (market_value_weighted(stocks, context.MV_SMA, 3) +market_value_weighted(stocks, context.MV_BIG, context.BM_BIG)) / 2# 获取小账面市值比组合的市值加权组合收益率hml_s = (market_value_weighted(stocks, context.MV_SMA, context.BM_SMA) +market_value_weighted(stocks, context.MV_BIG, context.BM_SMA)) / 2hml = hml_b - hml_s# 获取市场收益率close = history_n(symbol='SHSE.000300', frequency='1d', count=context.date + 1,end_time=last_day, fields='close', skip_suspended=True,fill_missing='Last', adjust=ADJUST_PREV, df=True)['close'].valuesmarket_return = close[-1] / close[0] - 1coff_pool = []# 对每只股票进行回归获取其alpha值for stock in stocks.index:x_value = np.array([[market_return], [smb], [hml], [1.0]])y_value = np.array([stocks['return'][stock]])# OLS估计系数coff = np.linalg.lstsq(x_value.T, y_value)[0][3]coff_pool.append(coff)# 获取alpha最小并且小于0的10只的股票进行操作(若少于10只则全部买入)stocks['alpha'] = coff_poolstocks = stocks[stocks.alpha < 0].sort_values(by='alpha').head(10)symbols_pool = stocks.index.tolist()positions = context.account().positions()# 平不在标的池的股票for position in positions:symbol = position['symbol']if symbol not in symbols_pool:order_target_percent(symbol=symbol, percent=0, order_type=OrderType_Market,position_side=PositionSide_Long)print('市价单平不在标的池的', symbol)# 获取股票的权重percent = context.ratio / len(symbols_pool)# 买在标的池中的股票for symbol in symbols_pool:order_target_percent(symbol=symbol, percent=percent, order_type=OrderType_Market,position_side=PositionSide_Long)print(symbol, '以市价单调多仓到仓位', percent)if __name__ == '__main__':'''strategy_id策略ID,由系统生成filename文件名,请与本文件名保持一致mode实时模式:MODE_LIVE回测模式:MODE_BACKTESTtoken绑定计算机的ID,可在系统设置-密钥管理中生成backtest_start_time回测开始时间backtest_end_time回测结束时间backtest_adjust股票复权方式不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POSTbacktest_initial_cash回测初始资金backtest_commission_ratio回测佣金比例backtest_slippage_ratio回测滑点比例'''run(strategy_id='strategy_id',filename='main.py',mode=MODE_BACKTEST,token='token_id',backtest_start_time='2017-07-01 08:00:00',backtest_end_time='2017-10-01 16:00:00',backtest_adjust=ADJUST_PREV,backtest_initial_cash=10000000,backtest_commission_ratio=0.0001,backtest_slippage_ratio=0.0001)
4. 回测结果与稳健性检验
设定初始资金1000万,手续费率为0.01%,滑点比率为0.01%。回测结果如下图所示。
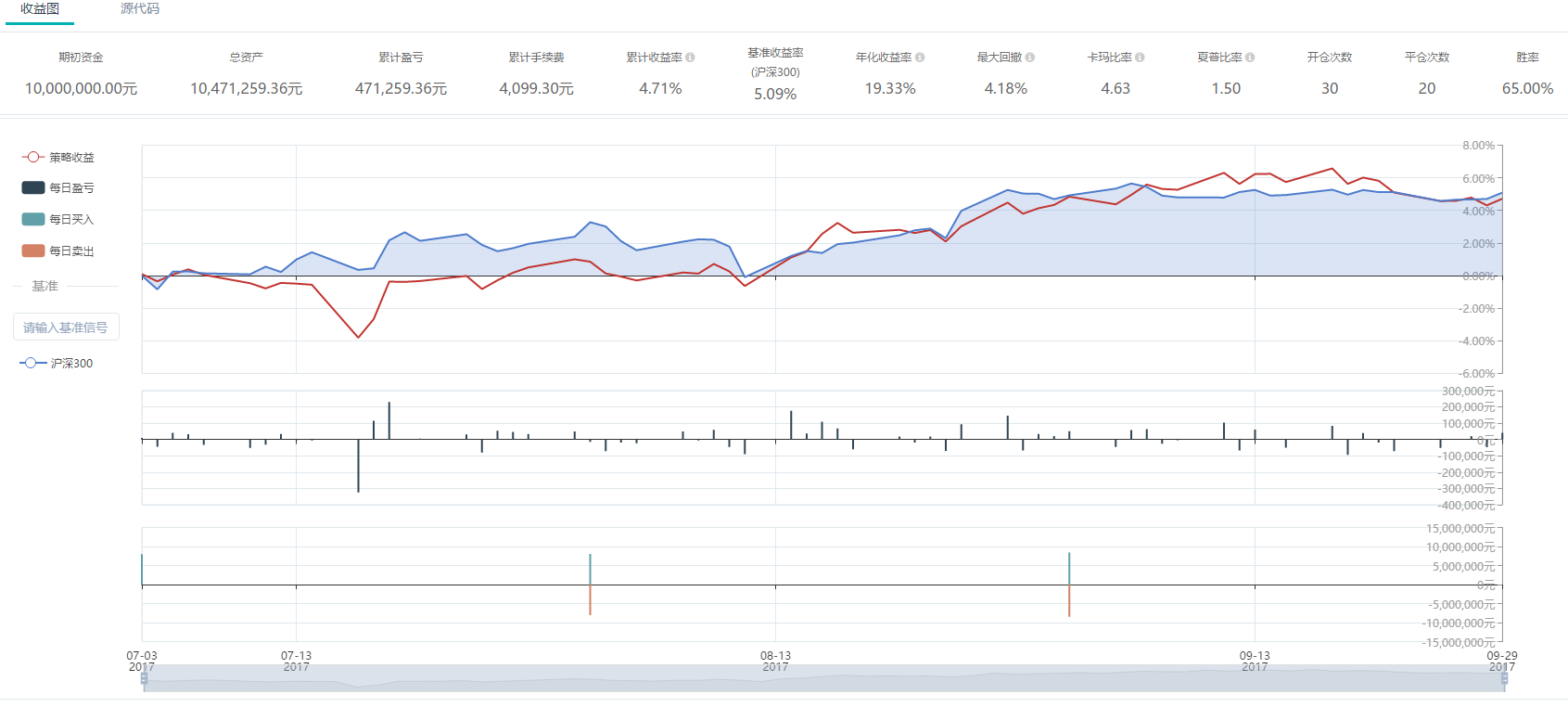
回测期累计收益为4.71%,年化收益率为19.33%,沪深300指数收益率为5.09%,策略整体跑输沪深300指数。最大回撤为4.18%,胜率为65%。
为了检验策略的稳健性,改变回测时间,得到回测结果如下。
| 回测时间 | 时间长度 | 年化收益率 | 最大回撤 |
|---|---|---|---|
| 2017.07.01-2017.10.01 | 3个月 | 19.33% | 4.18% |
| 2017.07.01-2017.12.31 | 5个月 | 12.54% | 7.53% |
| 2017.07.01-2018.07.01 | 12个月 | -8.09% | 23.17% |
| 2017.07.01-2019.07.01 | 24个月 | 3.27% | 35.38% |
| 2017.07.01-2020.07.01 | 36个月 | 6.19% | 35.37% |
由上表可以看出,策略收益除了在2017年7月1日至2018年7月1日以外其他时间段收益均为正。在2017年7月1日至2017年10月1日期间收益率最高,年化收益率为19.33%。回测期最大回撤随着时间长度的增加而增加,最高达到35.38%,与获得的收益相比,承受风险过大。
注:此策略只用于学习、交流、演示,不构成任何投资建议。


 工商网监
工商网监
