

文件单功能使用指南
功能简介
掘金终端提供了一种委托指令的处理方式,让用户的委托指令,能够以文件的形式,提交给掘金终端进行报单处理,并通过文件的形式,获得相关交易数据的结果反馈。
什么是文件单?
- 文件单是记录用户的委托指令的数据文件,目前掘金终端支持 dbf 和 csv 这2种数据文件格式的文件单。
- 每个文件单中,包含1~n条记录,每条记录代表一笔委托指令
- 文件单中的字段来描述每笔委托指令的参数,具体的字段请参考下文的
接入规范
文件单处理流程
- 流程如下图所示:

快速上手
下文的示例中,我们将创建一个仿真的交易账户,进行相应的配置,开启文件单功能。
准备交易账户
在 账户管理 下 仿真账户 界面下,添加仿真账户。 我们新建一个账户,名称为 王富贵

在 账户管理 下 仿真账户 界面下,为刚创建的仿真账户转入资金,以便进行测试。

配置文件单功能
进入配置界面
在 交易工具 界面下,选择 文件单, 进入文件单配置界面,如下图所示: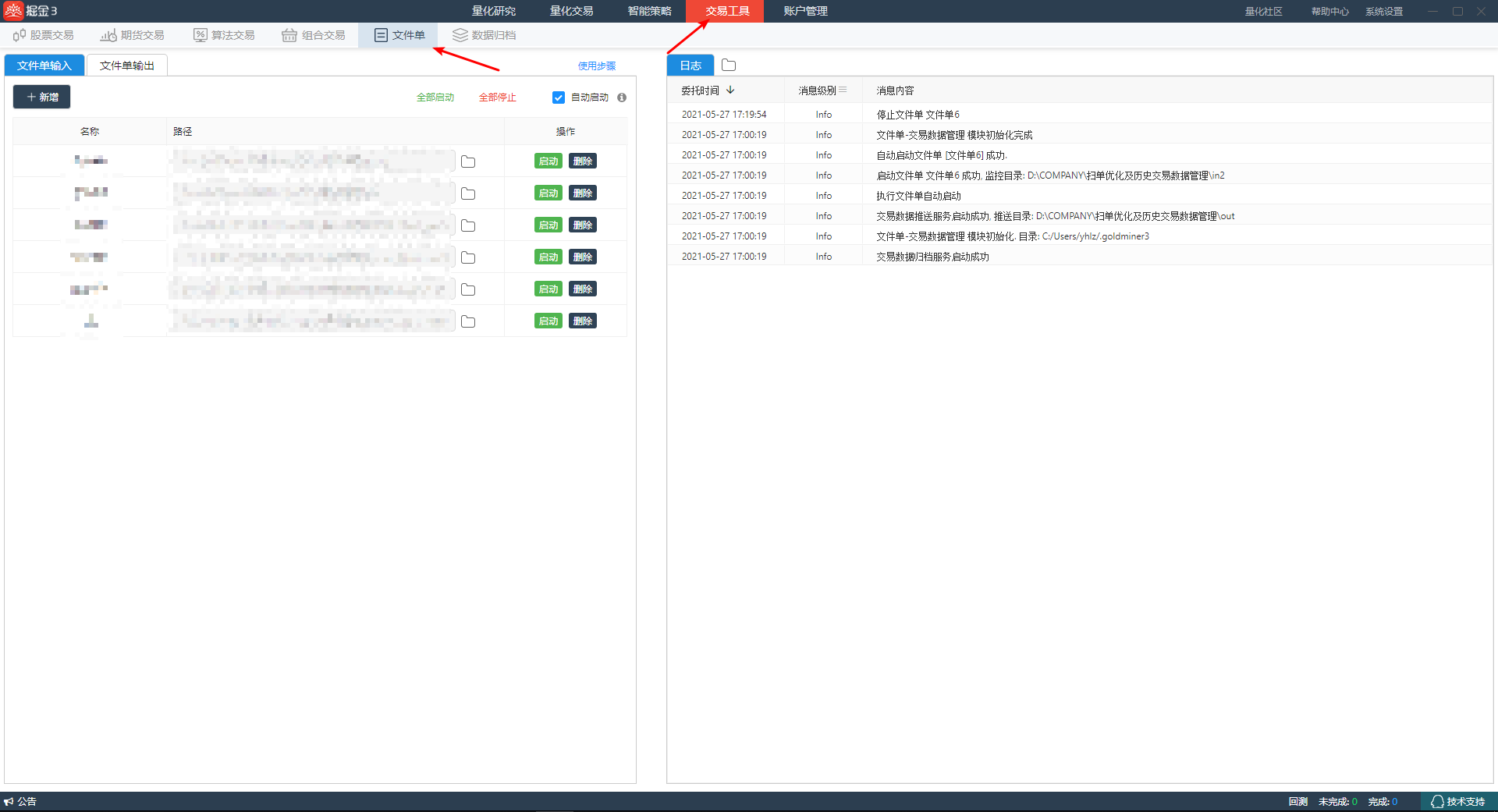
文件单输入配置
- 新增一个文件单配置,名称为 王富贵的文件单
- 设置文件单的输入目录的路径为: C:\test\scan_order

文件单输出配置
- 如果我们的下单的策略需要获取委托执行后的反馈数据,则需要开启对应交易账户的文件单输出
- 文件单输出的数据项分成6类, 每类数据对应一个数据文件
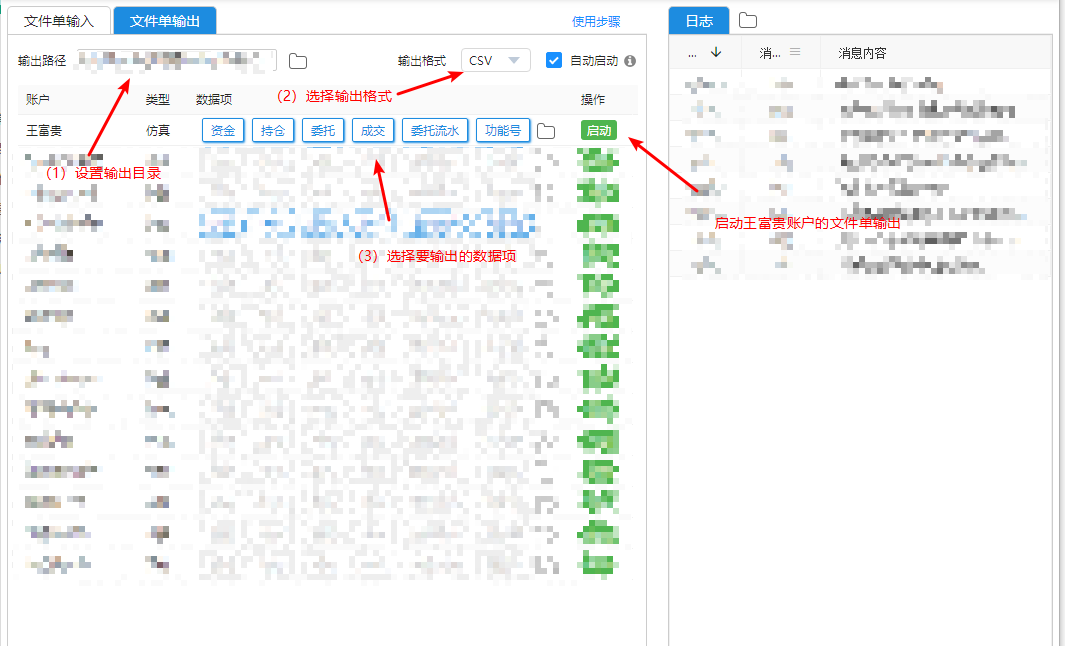
文件单输出目录结构说明
以上图的配置为例,在文件单的输出目录 C:\test\push , 会为每个 启动 了文件单输出的交易账户,创建一个以交易账户ID为名称的子目录,在该子目录下输出相应的数据项文件。例如:王富贵的账户ID为:1395dc4f-3601-11eb-bda5-001018b67b94,C:\test\push目录下结构如下所示:
C:\test\push├── 1395dc4f-3601-11eb-bda5-001018b67b94│ ├── cash.csv│ ├── execution_report.csv│ ├── func_response.csv│ ├── order_status.csv│ ├── order_status_change.csv│ └── position.csv└── readme.txt
数据项与文件名的对应关系,请看下表:
| csv格式文件名 | dbf格式文件名 | 数据项 |
|---|---|---|
| cash.csv | cash.dbf | 交易账户资金数据 |
| position.csv | position.dbf | 交易账户持仓数据 |
| order_status.csv | order_status.dbf | 日内委托数据 |
| execution_report.csv | execution_report.dbf | 委托执行回报数据 |
| order_status_change.csv | order_status_change.dbf | 委托状态变更流水记录 |
| func_response.csv | func_response.dbf | 功能号执行结果数据 |
启动文件单输入
- 准备下单前,请检查使用文件单输入配置是 启动状态
勾选自动启动,可以自动启动重启终端时未停止的文件单
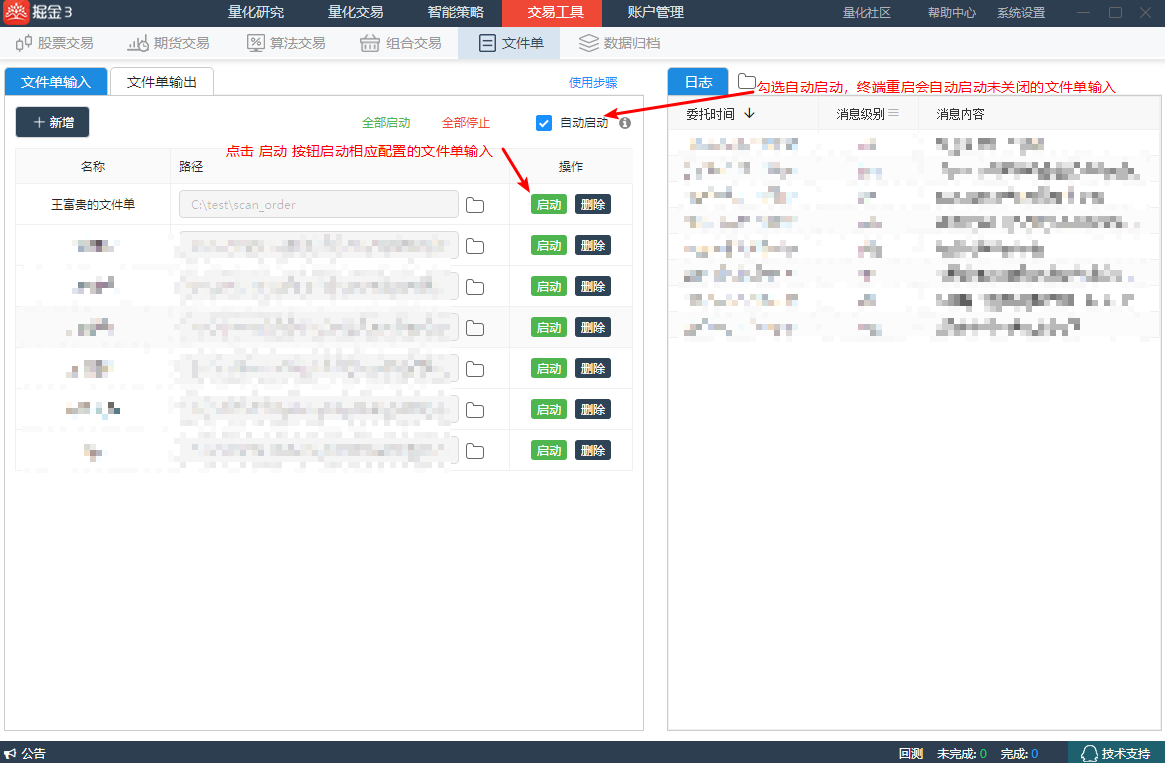
启动文件单输出
准备下单前,请检查使用的交易账户的文件单输出是 启动状态
- 如果您的策略程序不需要用到文件单输出的数据,则可以不开启

检查交易账户的连接状态
- 准备下单前,请检查使用的交易账户当前处于 已连接 状态

执行策略程序下发文件单
策略程序请参考示例策略,内含示例策略使用说明。下载地址:示例策略
策略程序接入文件单服务注意事项
启动文件单服务后, 策略程序就可以向文件单的输入目录下写委托文件了. 在此处, 我们特别补充说明一下文件单服务, 扫描文件单目录的工作机制, 并给出在进行策略程序编写时应该注意的事项.
文件单目录委托文件扫描的工作流程和机制
文件单服务启动后, 就会监控目录, 当有对应的委托文件(后缀 .csv 或者 .dbf)新增(或者已经存在的), 开始对委托文件进行扫描, 检测文件内容变化.
策略程序此时可以在文件单目录中创建委托文件, 向委托文件中追加委托指令.
文件单服务扫描到委托文件内容发生变化, 读取新增的委托指令进行处理(执行报单)
注意事项
关于启动顺序
- 建议: 先启动文件单输入, 再启动文件单输出, 检查交易账户的连接状态, 最后再启动用户的策略程序
- 建议: 启动文件单输入之前, 请先检查文件单目录是否为空. 如果不为空, 请手动删除, 让目录为空.
文件单的下单使用场景
- 场景1: 向同一个委托文件中不断追加新的委托指令
- 场景2: 分批次下达委托指令, 每一批委托指令使用一个委托文件.
- 场景3: 在其他目录通过手工或者其他程序创建好一个委托文件, 然后把这个委托文件复制到文件单的目录下, 等待文件单服务检测到该委托文件, 读取并执行委托指令.
委托文件的自动清理
我们提供了一种称之为 .fin 标志文件 的机制, 用来通知文件单服务, 对应的委托文件已经不会再追加新的委托指令了. 等处理完文件中的委托指令后, 可以由文件单服务进行清理操作.
.fin 是 finished 的简称, 表示该文件已经使用完毕, 策略程序不会再追加新的委托指令到文件了.
.fin 标志文件 的用法具体如下文描述:
.fin 标志文件 机制
下面以 csv 格式的委托文件为例进行说明. dbf 文件与之类似, 只是把文件名中的 csv 换成 dbf.
- 下达委托交易的 csv 委托文件, 文件名为: 2020-10-15_10:48:09.072.order.csv
- 所有委托已经追加完毕, 不会再向此文件追加委托指令了. 我们的策略程序需要按照流程做如下几件事情:
- 关闭委托文件. 此例中, 是策略程序需要关闭 2020-10-15_10:48:09.072.order.csv 文件.
- 在文件单输入目录下, 创建对应的 .fin 标志文件. 文件名是在委托文件的文件名后, 添加 .fin 后缀, 在此例中, 委托文件对应的 .fin 文件的文件名为: 2020-10-15_10:48:09.072.order.csv.fin
- 确保策略程序没有打开对应 .fin 标志文件. 在此例中, 策略程序需要保证没有打开 2020-10-15_10:48:09.072.order.csv.fin 文件.
- 执行了以上3步后, 文件单服务在执行完委托文件中的委托指令后, 会自动清除委托文件和对应的 .fin 标志文件.
为什么要有 .fin 文件机制呢?
- 没有 .fin 标志文件, 文件单服务无法判断这个委托文件是否已经使用完毕, 不会再追加新的委托指令了. 这样文件单服务在运行期间,就会持续扫描该委托文件. 随着不断的新增委托文件, 需要扫描的文件数量就会增加, 这样就会无谓增加cpu消耗, 增大硬盘的IO操作负荷, 反而会降低文件单的执行效率.
- 委托文件是否还会追加新的委托指令, 这个只有策略程序才知道, 所以得由策略程序通过 .fin 标志文件 的机制, 通知文件单服务, 对应的委托文件已经不会再更新了, 可以交由文件单服务清理了.
为什么要确保文件关闭, 没有打开呢?
- 在windows系统下, 如果策略程序没有关闭委托文件, 没有关闭 .fin 标志文件, 文件单服务在尝试清理委托文件的时候, 会遇到文件被其他进程占用的问题,从而导致清理操作失败.
策略程序开发中的注意事项和最佳实践
在策略程序中, 向委托文件追加完委托指令的操作后, 因多数情况下, 我们使用的都是带缓冲的文件, 所以请执行诸如类似 flush() 的操作, 确保数据尽快刷新写入到磁盘的文件中, 这样文件单服务才能在第一时间内扫描到新增的委托指令, 提高下单速度.
python 语言的请参考: https://docs.python.org/zh-cn/3/library/io.html?highlight=flush#io.IOBase.flush
java 语言的请参考: https://tool.oschina.net/uploads/apidocs/jdk-zh/java/io/Flushable.html#flush()其他语言略…
不要每笔委托就产生一个委托文件,这样会产生大量的委托文件,从而引起性能问题. 可以采用向同一个委托文件追加委托指令的方式.
避免不停创建新的委托文件, 而没有对应的 .fin 标志文件. 这样会引起cpu和磁盘负荷不断增加, 从而导致掘金终端性能问题.
建议: 每天交易结束后, 按照上文描述的步骤, 创建对应的 .fin 文件, 通知文件单服务清理委托文件.
建议: 使用文件单服务, 请同时开启 数据归档 功能.
扫单性能
运行环境
- 掘金仿真柜台
- 操作系统:Windows 10,64位,SSD 固态硬盘
- 掘金版本:3.12.0
- 硬件配置:4核8G
委托场景
- 场景1:委托10笔,每次一笔,收到
已报确认后委托下一笔 - 场景2:委托100笔,每次一笔,收到
已报确认后委托下一笔 - 场景3:委托1000笔,每次一笔,收到
已报确认后委托下一笔
存量委托对文件单性能影响可忽略不计
测试结果
各测试场景下委托耗时,时间单位为毫秒.
CSV扫单性能数据结果
| 场景 | 最小值 | 中位数 | 平均值 |
|---|---|---|---|
| 场景1 | 10.9706 | 10.9206 | 11.0704 |
| 场景2 | 10.9701 | 10.9706 | 11.7486 |
| 场景3 | 10.9611 | 11.0560 | 11.7765 |
DBF扫单性能数据结果
| 场景 | 最小值 | 中位数 | 平均值 |
|---|---|---|---|
| 场景1 | 8.9960 | 13.0940 | 17.9999 |
| 场景2 | 7.9960 | 14.0015 | 18.5304 |
| 场景3 | 6.9980 | 14.0075 | 21.7687 |
测试脚本
测试所用脚本,包含在扫单示例策略源码中。
注意事项
- 文件单的输入目录和输出目录所在磁盘,最好使用SSD磁盘,能够有效降低磁盘读写操作而引起的延时,进一步提高报单速度。
- 请勿使用如网络位置的硬盘、WSL(windows虚拟的linux环境)等较为小众环境,在一定情况下会因磁盘读写不稳定造成数据丢失。
- 因为受 dbf 文件格式规范的内,字符串字段的内容最大长度不能超过 254 个 ANSI 字符。所以,如果要使用的功能号请的 func_args 字段的值,或者返回结果的 data 字段的值得长度超出了限制,请改用 csv 格式的文件单。
- 推荐开启 数据归档 功能。开启后,会将交易过程中产生的交易数据进行归档保存。方便进行盘后数据分析,并提供了报单速度统计,异常合约检测功能。
- 扫单功能是通过刷新文件来传递数据由于公网复杂环境以及磁盘IO导致的延迟可能会出现回推数据变更不及时,使用时如出现不同回推文件出现信息不一致的情况,可以等待一段时间后反复查询以确保一致
- DBF文件定义字段长度超过实际字符长度会默认用空格来填充剩余长度。取数据凡是字符串类型的数据需要去掉空格。
- DBF格式扫回推信息会存在中文,解析是需要指定utf编码格式。在python中使用dbf库可以在创建table时指定codepage:
dbf.Table(dbf_file, codepage='utf8') - order_status_change 是流水表,如果交易途中没有开启下行,没有收到的数据会丢失。
开启数据归档
请按下图所示,开启数据归档功能。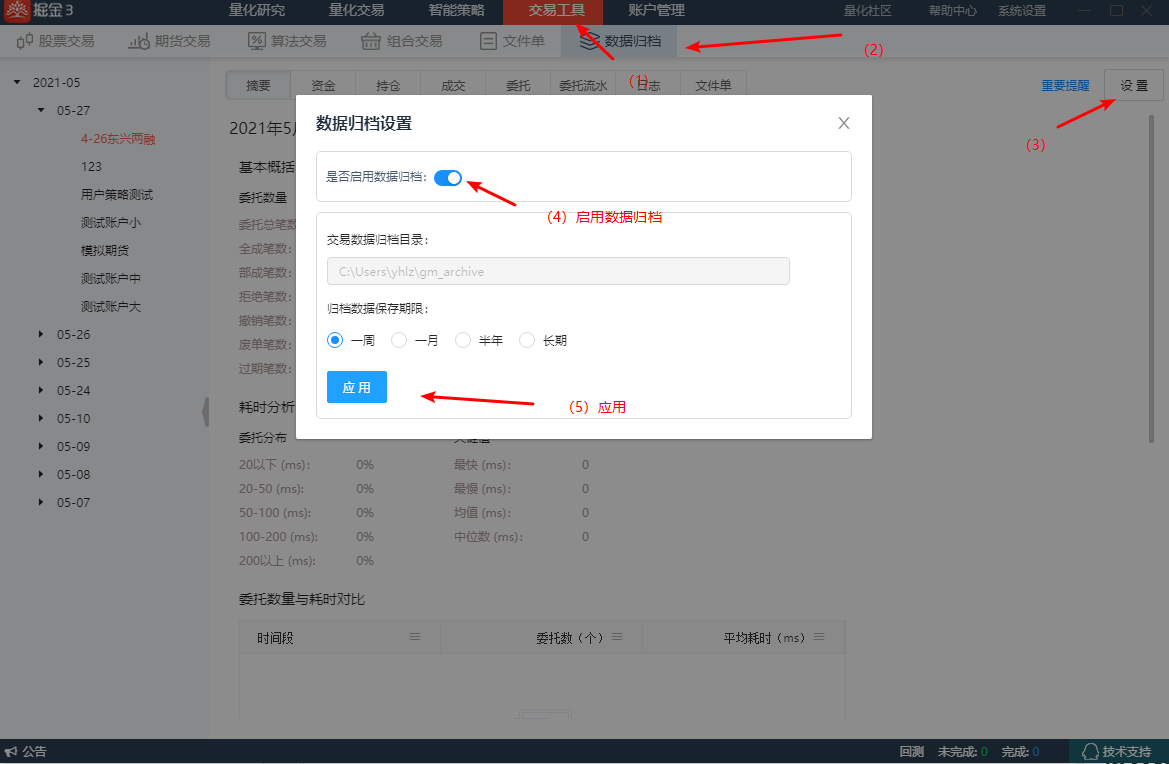
接入规范
文件单的输入和输出,现在支持 dbf 和 csv 这2种格式,请根据选择,查看对应的接入规范文档


 工商网监
工商网监
